

Co-authored by Courtney Pacheco and Ralph Bean
Note: This article is a follow-up to Introduction to Modularity.
Introduction

The purpose of our Modularity initiative is to support the building, maintaining, and shipping of modular things. So, in order to ensure these three requirements are met, we need to design a framework for building and composing the distribution.
In terms of the framework, in general, we are concerned about the possibility of creating an exponential number of component combinations with independent lifecycles. That is, when the number of component combinations becomes too large, we will not be able to manage them. So that we don’t accidentally make our lives worse, we must limit the number of supported modules with a policy and provide infrastructure automation to reduce the amount of manual work required.
Submitting Packages vs. Submitting Modules
Normally, a packager identifies an upstream project to package, writes/generates a spec file, builds locally in mock or scratch in koji, evaluates/decides whether to proceed with the packaging, then submits the package review in rhbz. With modules, the packager simply writes a .yaml file (which defines the module’s metadata), then submits it for review in rhbz. This approach for defining modules is designed to be as simple as possible to minimize the complexity of the process.
Updating Packages vs. Updating Modules

Updating packages can be very complex. With modules, maintainers can easily update their module’s metadata definition (via the .yaml file), commit and push it to dist-git (which houses the definitions of modules), then kick off a “module build” in Koji. Like the submission process for modules, this approach is intentionally designed to be as simple as possible (and as similar to the existing packaging process as possible).
Infrastructure Proposal
Ralph Bean created a very detailed, informative overview of the Infrastructure proposal:
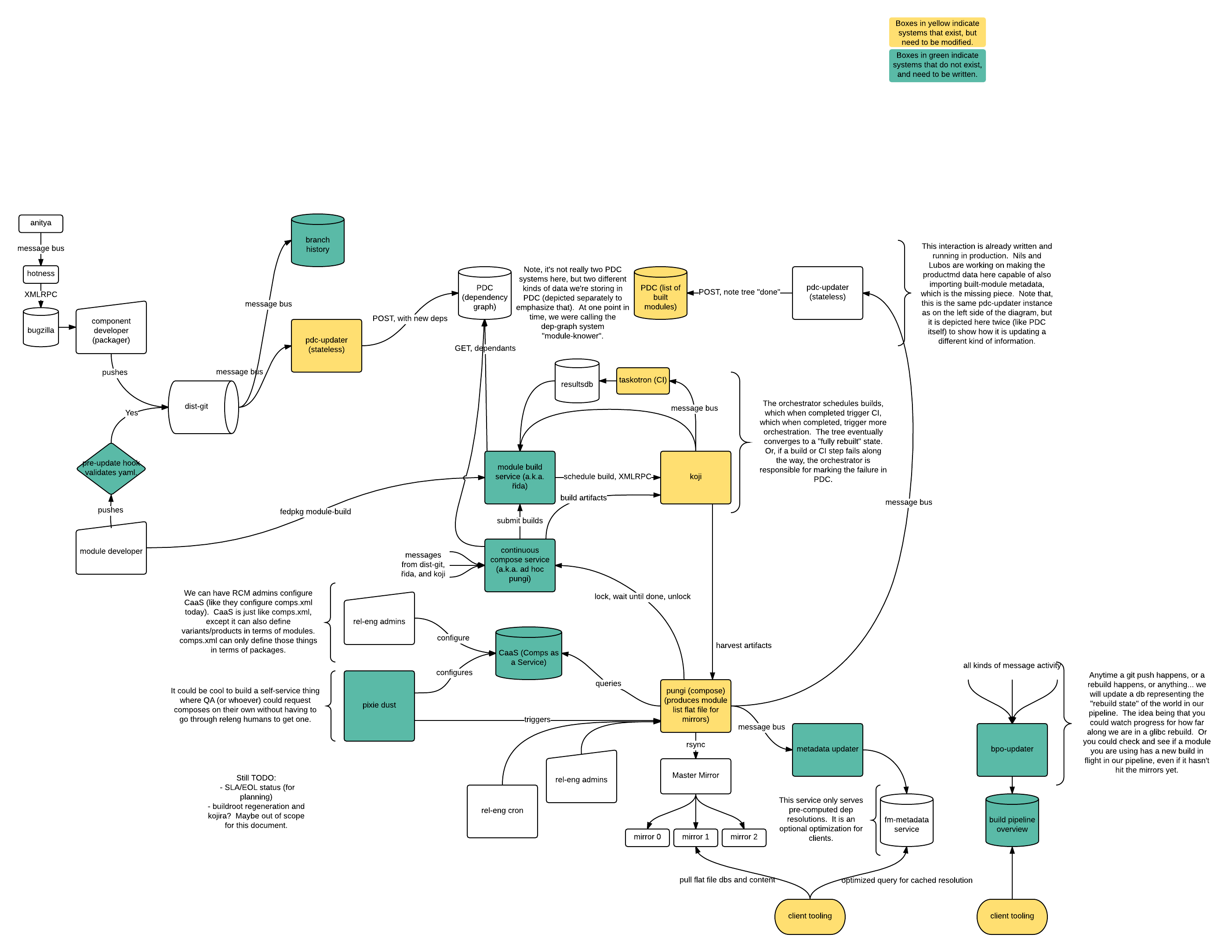
Full-size render here: https://fedoraproject.org/w/uploads/4/49/Modularity_Systems.png
Two important elements in this chart are captured in the box labeled Orchestrator (i.e., ad-hoc pungi). One part of that is říďa, the module-build service, which is responsible for setting up tags in Koji and rebuilding the components of a module from source. (Note: We demoed a working prototype of říďa at Flock 2016.) The other system here is a continuous rebuild/compose system, which makes heavy use of the Product Definition Center (PDC) to know what needs to be rebuilt. That is, when a component in a module changes, the continuous compose system is responsible for asking what depends on that component, then scheduling rebuilds of those modules directly in říďa.
Once those module rebuilds have completed and validated by CI, the continuous compose system will be triggered again to schedule rebuilds of a subsequent tier of dependencies, and this cycle will repeated until the tree of dependencies is fully rebuilt.
In the event that a rebuild fails, or if CI validation fails, maintainers will be notified in the usual ways (the Fedora notification service). A module maintainer could then respond by manually fixing their module and scheduling another module build (in koji), at which point the trio of systems would pick up where they left off and would complete the rebuild of subsequent tiers (stacks).
You can find more details about říďa here. You can also find more details about the components in the rest of the proposal chart here.
How you can help Modularity

Would you like to learn more? Would you like to help out? You can find us on #fedora-modularity on freenode. You can also join the weekly Modularity Working Group Meeting for the latest updates on Modularity.
Also, please do subscribe to devel@lists.fedoraproject.com for regular updates on our Modularity effort! In case you missed our email updates, you can find archives for this list here.

{kind=link}
{kind=link}
Start the discussion by commenting on the auto-created topic at discussion.fedoraproject.org